Hadoop 大数据基础信息(一)
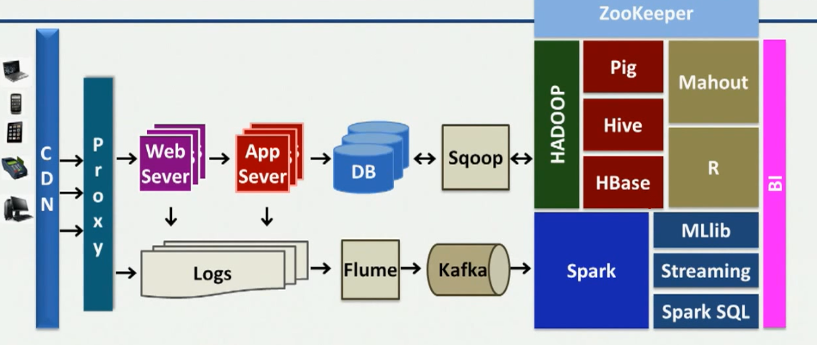
大数据生态系统
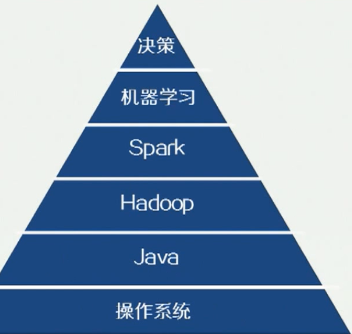
Java-大数据的基石
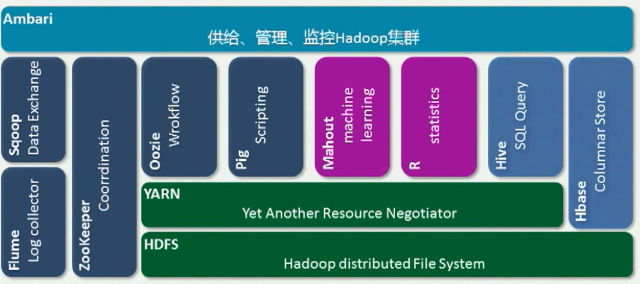
Hadoop生态圈
-
Hive
-
Hive依赖HDFS进行存储,表是逻辑表
-
Hive的SQL翻译成MR执行
-
Hive可以将结构化数据映射成一张单表
-
OLAP,重在分析和统计
-
不支持低延迟操作
-
不提供row level更新
-
适用于批处理
-
操作类似于MySQL
-
-
Pig
-
大规模数据分析平台
-
提供类SQL语言-Pig Latin
-
将SQL请求转化为优化的MR作业
-
操作API都非常简单
-
过程式语言
-
支持UDF,易于重用
-
-
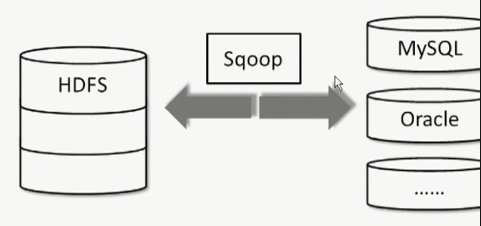
Sqoop
-
Hadoop和RDBMS之间高效传输的工具
-
Apache顶级项目
-
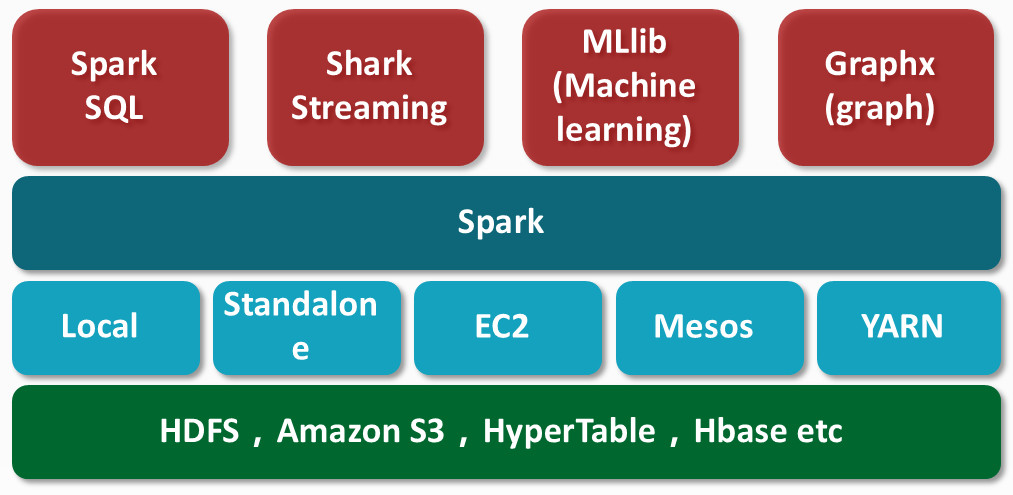
Spark技术生态圈
-
Spark SQL
-
操作结构和数据的Spark模块
-
无缝混合SQL查询到Spark程序中
-
一致性的数据访问
使用通用方式访问各种数据源,Hive,avro,JDBC等,甚至可以跨数据源
-
Hive兼容性
执行无需修改Hive查询
-
标准连接
提供JDBC或ODBC的标准连接用于BI
-
-
MLlib
-
Spark上分布式机器学习框架
-
分布式存储器式架构比Hadoop磁盘式的Mahout快10倍以上
-
MLlib可以使用许多常见的机器学习算法 分类 回归 聚类 协同过滤等
-
Apache Mahout原来针对Hadoop的机器学习库现已脱离MapReduce,转而加入Spark的MLlib
-
-
GraphX
-
GraphX是Spark针对图和图并行计算的API
-
灵活性
将图和集合进行无缝集成在一起
-
速度快
可以和最快的专业图形处理系统媲美
-
算法
不断增长的图形算法类库,很多由用户贡献
-