Hadoop Hadoop架构分析(四)
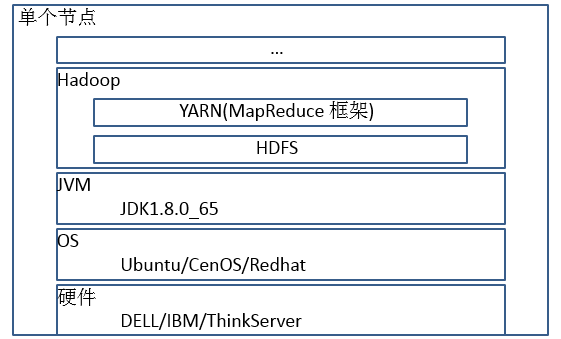
节点架构
单节点体系
集群架构
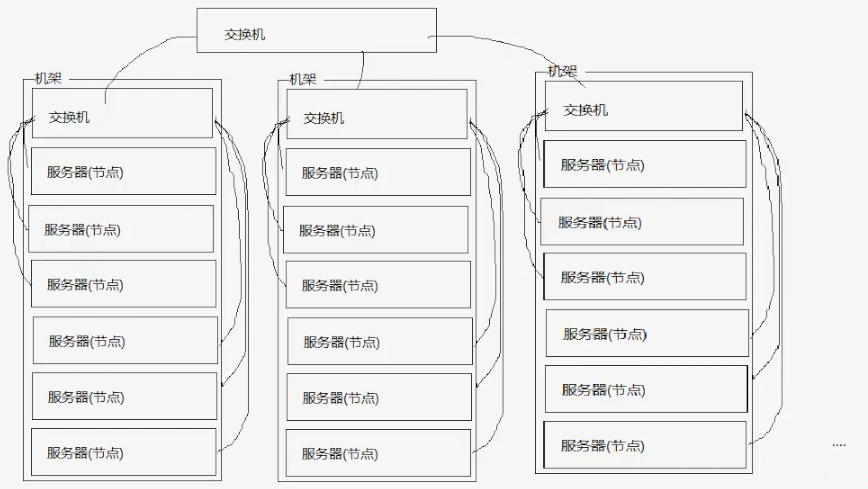
节点(进程)之间的距离:到达共同节点距离之和
-
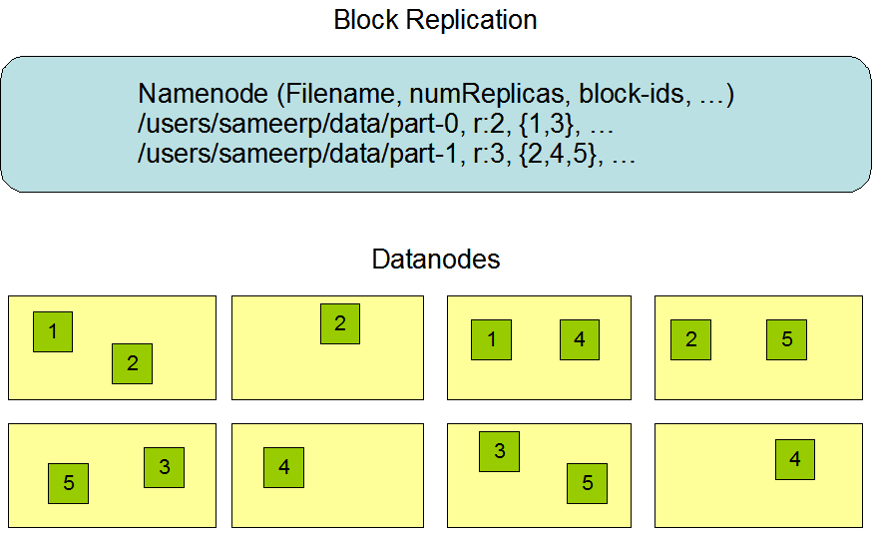
副本存放策略
-
V1
同一个机架放2分,另一份放到其他机架(当前节点为存储节点)
-
V2
在一个机架上放1分,另外2分放到其他机架,防止断点数据丢失(当前节点为存储节点)
-
如果不是在数据节点上存放数据,hadoop会随机选一个机架存放,其余数据存放到其他机架
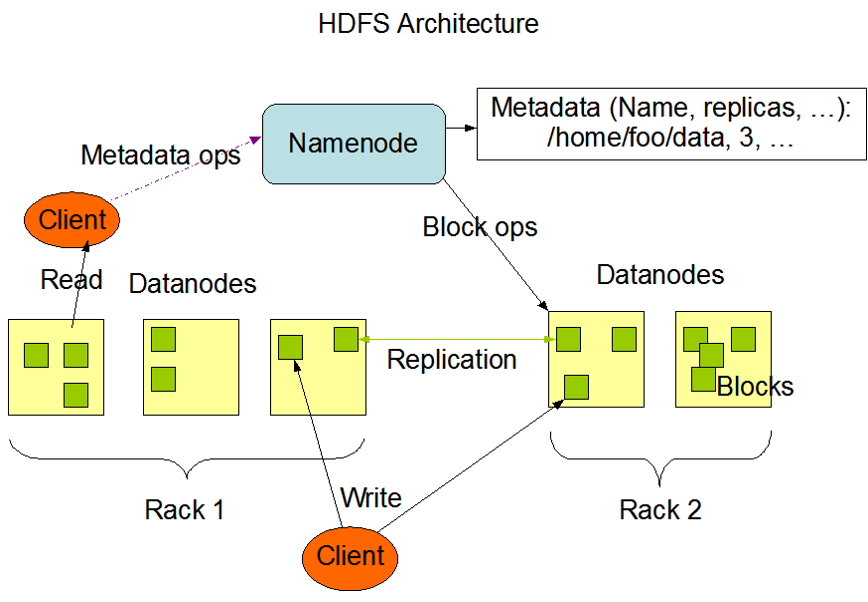
HDFS架构
Hadoop架构分析
-
Hadoop分布式文件系统
-
按需定制MapReduce
-
目标在于多次的文件流读取
-
写入成本很高
-
高度数据冗余(副本,默认3)
-
每个节点不需要RAID-独立磁盘冗余阵列 redundant array of independent disks
-
Blocksize较大(128m)(V1为64M)
-
定制节点的位置感知
NameNode
-
存储文件元数据,比如目录结构
-
运行NameNode的服务器至关重要,只有1个
-
只对元数据的增删做日志记录,不对block和文件流做记录
-
DataNode故障时,负责创建更
DataNode
-
存储真实数据
-
可运行在多种文件系统上(ext3/4,NTFS …)
-
通知NameNode自己有哪些block
-
NameNode在同一机架创建放置一个副本,另一机架放置2个副本
HDFS架构
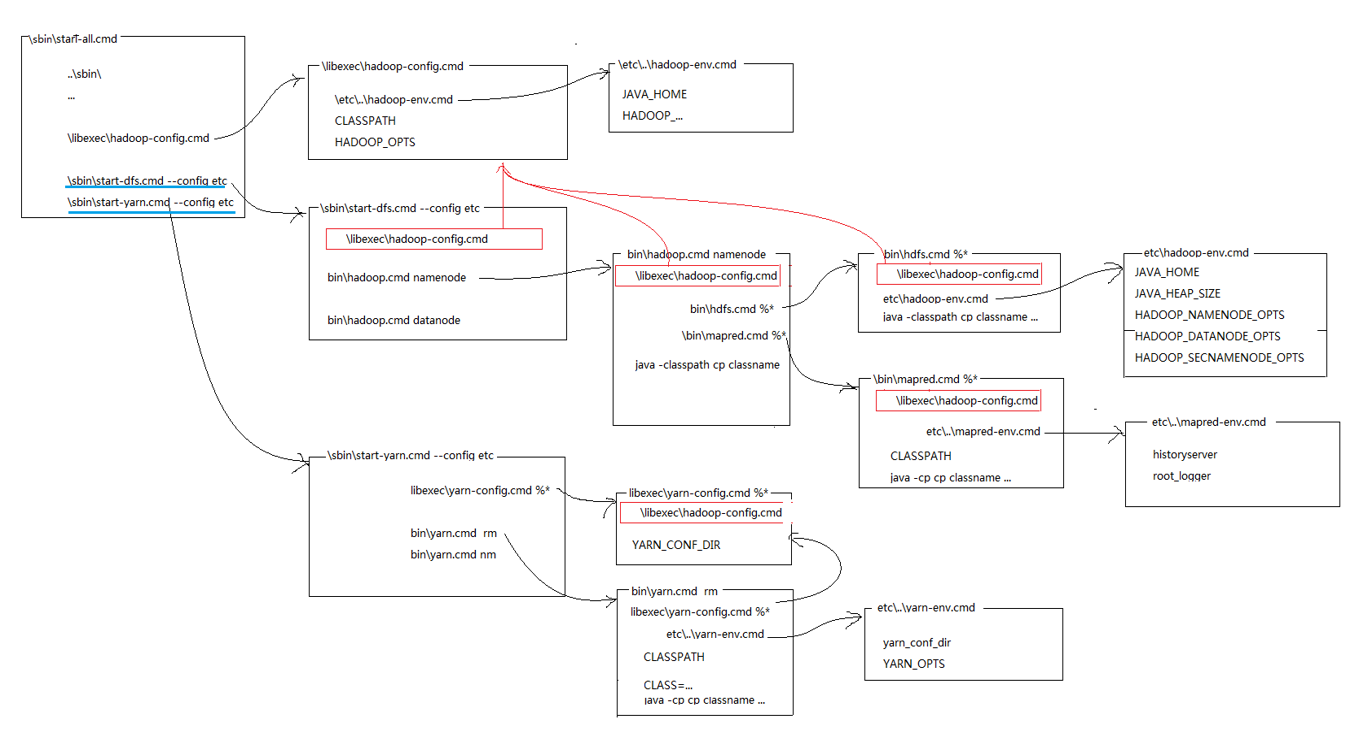
启动脚本分析
-
start-all.cmd
设置HADOOP_BIN_PATH为当前脚本所在目录(sbin)
过滤掉HADOOP_BIN_PATH后面的\
设置DEFAULT_LIBEXEC_DIR为libexec目录
调用hadoop-config.cmd
启动hdfs守护进程
启动yarn守护进程
-
hadoop-config.cmd
主要作用就是提取路径
如果指定--config选项则配置HADOOP_CONF_DIR,并调用HADOOP_CONF_DIR下的hadoop-env.cmd
如果指定--hosts选项则配置HADOOP_SLAVES为--hosts指定的文件的地址
判断JAVA_HOME等java参数
设置最大堆内存
HADOOP的堆大小会覆盖Java的堆大小
设置大量类路径
-
hadoop-env.cmd
设置JAVA_HOME
安全,日志相关
-
start-dfs.cmd
设置HADOOP_BIN_PATH为当前脚本所在目录(sbin)
调用hadoop-config.cmd
判断--config
启动namenode和datanode(start在新窗口启动)
-
hdfs.cmd
设置HADOOP_BIN_PATH为当前脚本所在目录(sbin)
调用hdfs-config.cmd和hadoop-env.cmd
-
hdfs-config.cmd
调用hadoop-config.cmd
-
hadoop.cmd
设置sbin路径
替换空格,左括号,右括号
调用hadoop-config.cmd
处理命令参数
定义hdf命令组
调用hdfs.cmd
定义mapreduce命令组
调用mapred.cmd
处理核心命令
fs -- set CLASS=org.apache.hadoop.fs.FsShell等
调用java程序
-
hdfs.cmd
定义标签组找到相应的类
-
mapred.cmd
定义mapreduce命令组
调用mapred-config.cmd
-
start-yarn.cmd
调用yarn-config.cmd
运行resourcemanger nodemanger proxyserver
总结