Hadoop MapReduce工作原理(六)
环境准备
进入符号链接的真实目录 cd -P link
start x启动图形界面
/etc/default/grub
sudo update-grub
cat /etc/issue 查看linux版本
重启
下载hdt,解压放到插件目录
添加Hadoop Location
Ctrl+Shift+T 查找类
MR端口为:50020,DFS端口为8020
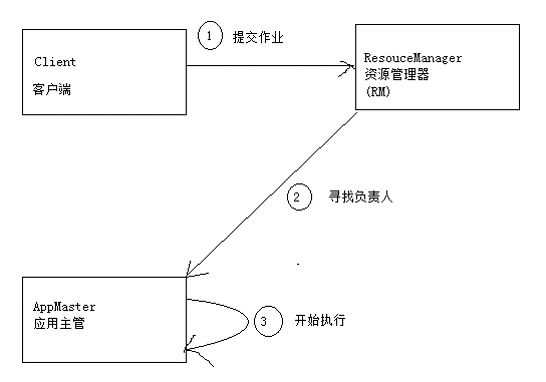
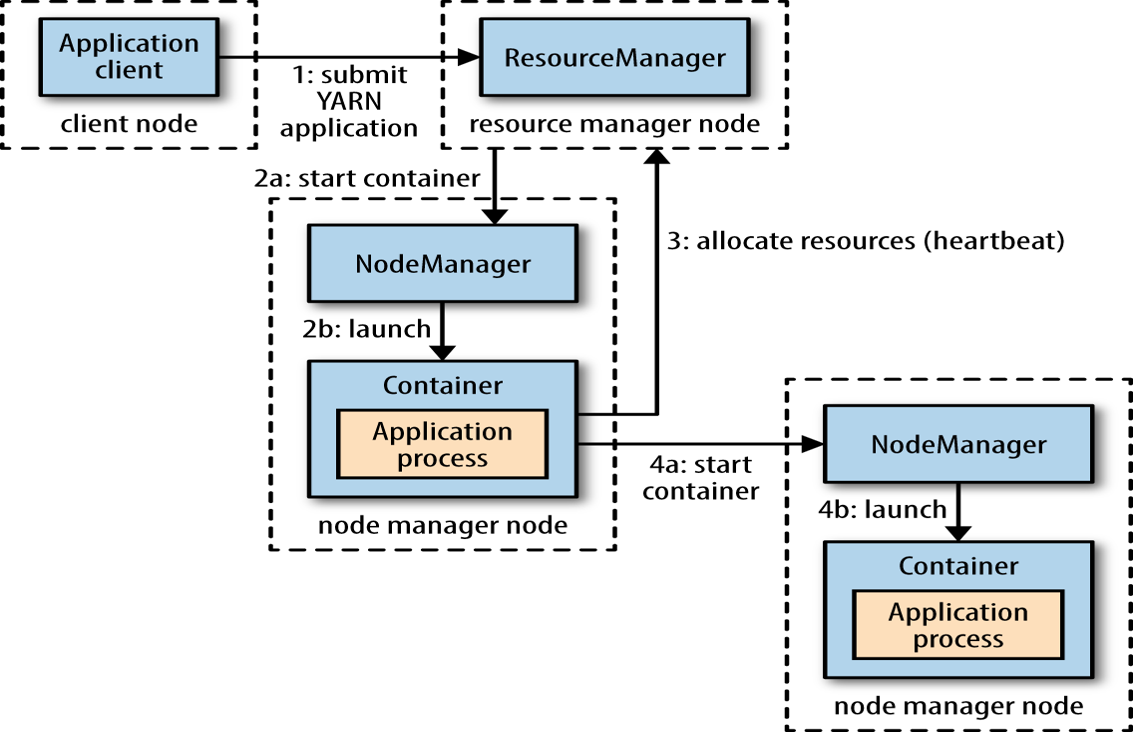
MR job的运行分析
-
client提交mr job
-
mr协调资源分配
-
nm启动并监控container
-
app master协调task
-
app master和task均由rm调度,由nm管理
-
hdfs用于在其他entity间共享job文件
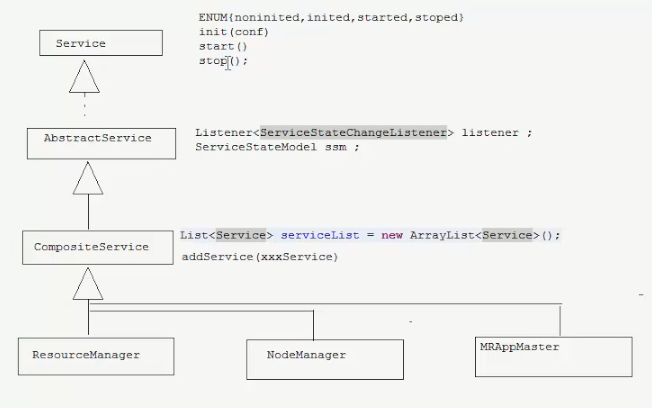
相关类
Job,ResourceManger,NodeManger,MrAPPMaster,NodeManger,MapTask,ReduceTask都有对应的java类
看说明(注释)
- Job
允许user配置,提交,控制执行,查询状态
setXXX()方法必须在submit之前调用
Job.getInstance();//JobConf ---> Job
- ResourceManger
集群中所有的资源都属于"我"管理
- NodeManger
ContainerMangerImpl(容器管理器)
ContainsLauncher(容器管理器启动器)
- MRAppmaster
状态机,封装了Job接口的实现,所有状态变化都通过job接口使其发生
每个时间会导致最终的状态变换
状态机变换是基于时事件的
组件之间收发事件,事件是载体
事件由核心的分发机制进行
- YarnChild
mrtask的主要进程 负责启动
- MapTask(旧版本) MapTaskImpl(新)
map任务封装
- ReduceTaskImpl
reduce任务封装
RM与NM与AM的体系结构
ClassNotFound错误
直接运行代码而不打包会出现ClassNotFound,因为setJarByClass根本找不到Jar包
使用ant
新建build.xml
<project name="hadoopdemo2" basedir="." default="package">
<target name="prepare">
<delete dir="${basedir}/build/classes" />
<mkdir dir="${basedir}/build/classes" />
</target>
<path id="path1">
<fileset dir="${basedir}/lib">
<include name="*.jar"/>
</fileset>
</path>
<target name="compile" depends="prepare">
<javac srcdir="${basedir}/src" destdir="${basedir}/build/classes" classpathref="path1" includeruntime="true"/>
</target>
<target name="package" depends="compile">
<jar destfile="${basedir}/lib/MyJar.jar" basedir="${basedir}/build/classes" />
</target>
</project>在主类中验证输出文件夹是否存在,并删除
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path outDir = new Path("/usr/out");
if(fs.exits(outDir)){
fs.delete(outDir,true);
}
Path tmpDir= new Path("/usr/out");
if(fs.exits(tmpDir)){
fs.delete(tmpDir,true);
}运行ant,把jar放到构建路径
运行java程序
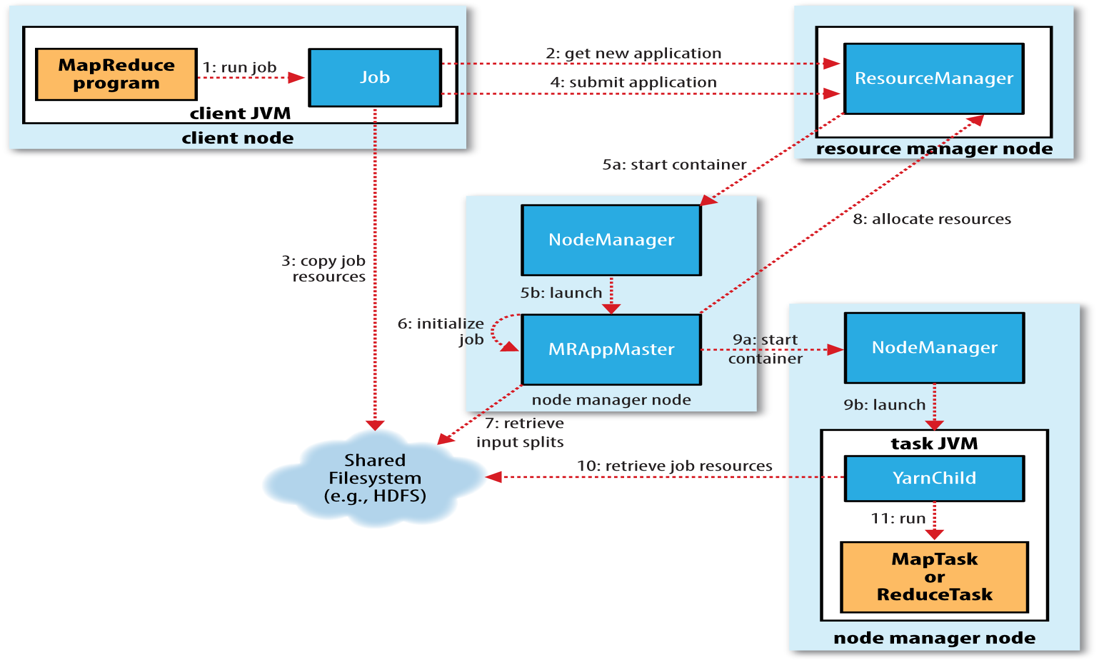
Job提交推演
submit()方法内部创建submitter并调用submitJobInternal()
submit过程如下:
-
请求rm获取appid,用做mr job id
-
检查output的有效性
-
计算input split
-
赋值资源(jar,conf,input split)到HDFS中,存放在以job id命名的目录下
-
jar文件在集群上有更多的副本,以备nm使用
-
rm.submitApplication()
Job初始化分析

java进程/核心Hadoop类
-
1.HDFS 数据存储
NameNode:org.apache.hadoop.hdfs.server.namenode.NameNode
DataNode:org.apache.hadoop.hdfs.server.datanode.DataNode
SecondaryNameNode:org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
-
2.yarn marpreduce作业调度
ResourceManger:org.apache.hadoop.yarn.server.resourcemanger.ResourceManger
NodeManger:org.apache.hadoop.yarn.server.nodemanger.NodeManger
-
5个主要的类
NameNode,DataNode,SecondaryNameNode,ResourceManger,NodeManger
他们都有main方法,都是Hadoop中的一个进程
start-dfs.sh(stop-dfs.sh)
hadoop namenode
hadoop datanode
hadoop secondaryNamenode
start-yarn.sh(stop-yarn.sh)
RM,NM
CapacityScheduler是Hadoop的默认调度器
job初始化
-
rm收到submitApp()后将请求转给Yarn scheduler
-
scheduler分配container
-
rm在该container启动app master , 并交由nm管理。
-
app master创建多个记录对象跟踪job进度,它将接受task的进度或完成报告。
-
检索input split
-
为每个split创建map任务和一定数量的reduce任务(setNumRed..()),此时分配jobid
-
app master判断如何运行task,如果是小job,app master会在同一jvm中运行
-
uber task就是指这一点,因为开启新容器分配和运行程序更耗费资源。
-
小job的衡量标准是map<10,只有reduce=1,而且input size < block size。这些值可以修改。
mapreduce.job.ubertask.maxmaps
mapreduce.job.ubertask.maxreduces
mapreduce.job.ubertask.enable -
最后,App master调用OutputCommitter的setupJob()方法,默认是FileOutputCommimter,主要是创建output目录和临时工作目录。
ResourceManger远程调试
启用ResourceManger程序的JVM远程调试
-
1.要先启动hadoop集群,在设置改变量,否则启动集群会一直等待。
-
2.设置YARN_RESOURCEMANAGER_OPTS变量开启调试
a.运行java程序时,直接指定参数:-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8000
b.先设置环境变量,再启动jvm,直接把环境变量附加在jvm启动参数之后
export YARN_RESOURCEMANAGER_OPTS =
"-agentlib:jdwp=transport=dt_socket,
server=y,suspend=y,address=8000"可以编写脚本enable-rarn-remotedebug.sh
记得source
-
3.导出eclipse程序的jar文件发送到集群上准备运行(客户端必须有ResourceManger的代码)
-
4.在集群上运行jar程序,会发现地址不动,因为在等待远程调试器进行连接。
start-yarn.sh -
5.在客户端设置程序中的断点(main)
-
6.设置eclipse的app远程调试选项,选择run--> debug configuration...->new remote deug...->socket attach -> 指定远程服务器ip和端口 ip:xx | port:8000
-
7.单步进行调试工作.
-
8.调试完成后记得在服务器上的远程调试选项关闭。export YARN_RESOURCEMANAGER_OPTS =