Hbase 介绍(一)
Hbase简介
HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java。它是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable 规模的服务。因此,它可以容错地存储海量稀疏的数据。
HBase在列上实现了BigTable论文提到的压缩算法、内存操作和布隆过滤器。HBase的表能够作为MapReduce任务的输入和输出,可以通过Java API来访问数据,也可以通过REST、Avro或者Thrift的API来访问。
虽然最近性能有了显著的提升,HBase 还不能直接取代SQL数据库。如今,它已经应用于多个数据驱动型网站,包括 Facebook的消息平台。
Hbase列族
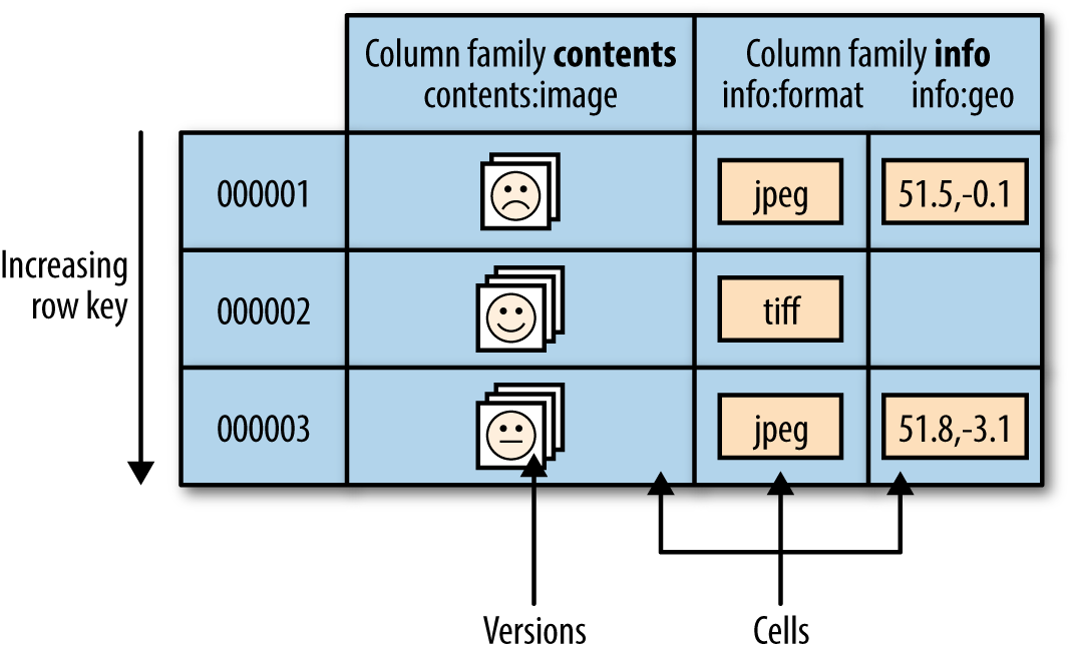
Hbase Regions
-
自动水平分区
-
row的子集
-
第一行(include),最后一行(exclude)
-
每张表至少一个region
-
增长到阀值时,切割成两个相同的region
-
row update是原子性的
Hbase架构
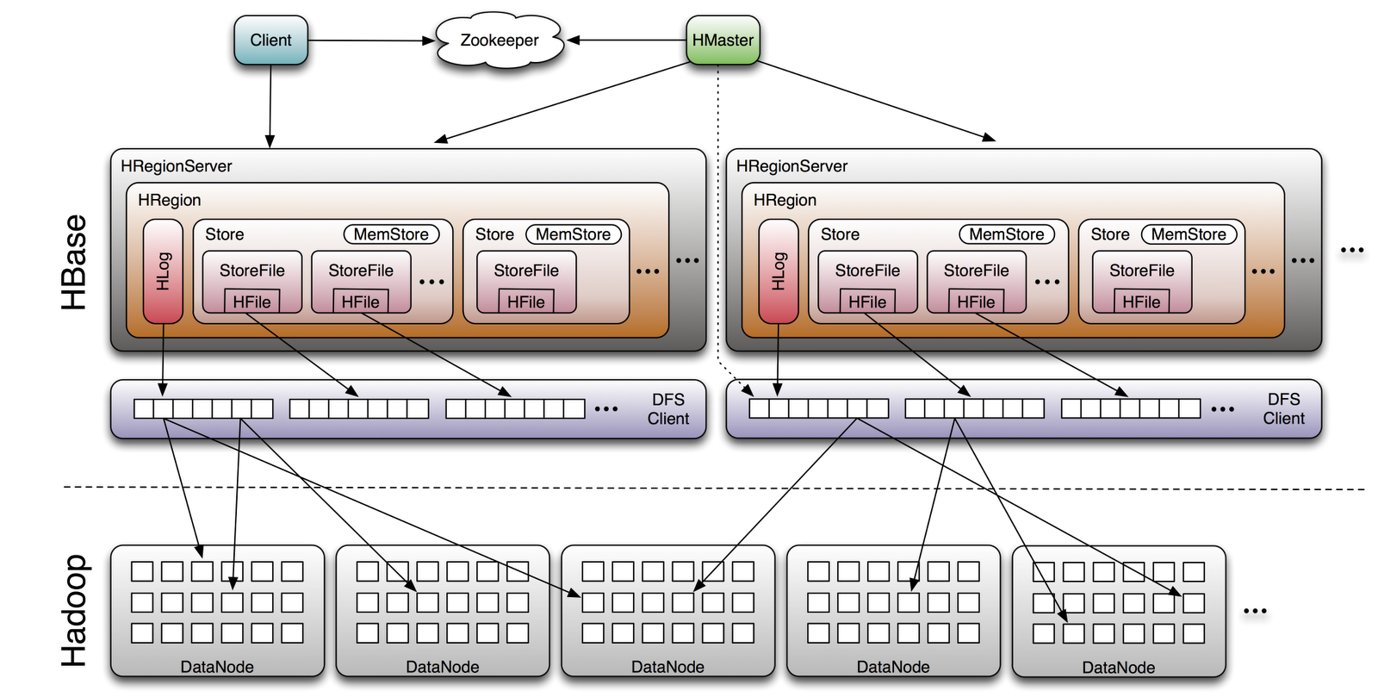
Hbase构成
-
Hbase master(1)
-
负责初始安装
-
指定region到regionserver
-
恢复故障的rs
-
轻负载
-
-
Hbase ReginServer(n)
-
携带0~n个region
-
负责客户端rw请求。
-
管理region split
-
通知master新的子region
-
管理offline的父代region以及对其的替换。
-
-
Hbase依赖于zk
-
默认HBase管理ZK
- start/stop
-
HMaster和HRS在zk中进行注册
-
依赖ZooKeeper
-
rs服务器列在conf/regionservers文件中
-
集群配制conf/hbase-site.xml和hbase-env.sh
-
Hbase可以在local,也可以在hdfs上存储数据
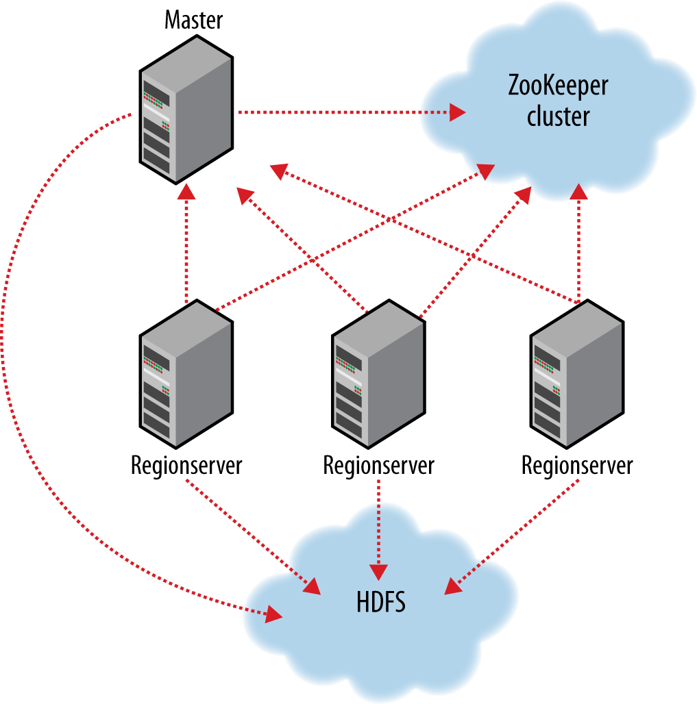
Hbase操作
-
hbase:meta
-
内部表
-
存放集群中all user-space region的当前列表、状态和位置
-
条目构成:表名,起始行,创建时间.md5哈希值
TestTable,xyz,1279729913622.1b6e176fb8d8aa88fd4ab6bc80247ece.
md5哈希值是对前三项的计算。
region变化是同步更新该表。
-
连接到zk集群的connection首先感知hbase:meta表,定位用户的区域和位置,之后再和rs交互。
-
为节省保存每行时hbase所做的3次轮询,缓存row启动和停止位置,client使用缓存的数据直到出错,此时client会再访问meta表。如果meta中的数据被删除,就会重新访问zk。
-
写操作先追加到提交log,然后进入内存,内存充满再写入filesystem。
-
提交日志位于hdfs上,当master发现故障的rs不可达时,就会按区域分离故障rs的提交日志,故障rs的区域挑选出分离的故障日志并重做到故障前的状态。
-
读操作时,先访问内存库,如果版本足够,操作即完成,否则依次访问清理文件,从最新到最老,知道版本满足条件。
-
Hbase数据模型
- 基于Google的bigtable模型(key-value对)
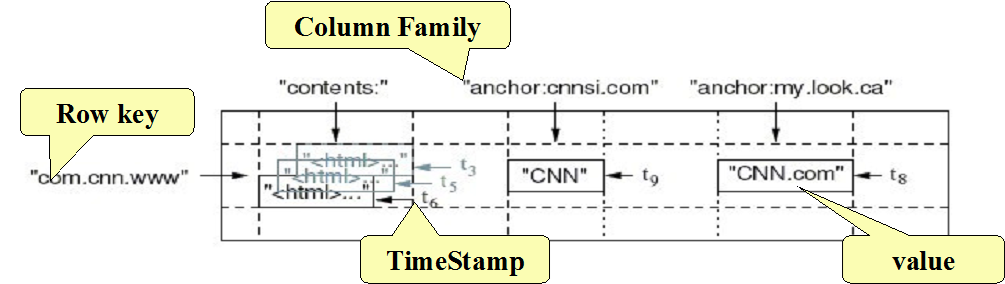
Hbase逻辑视图
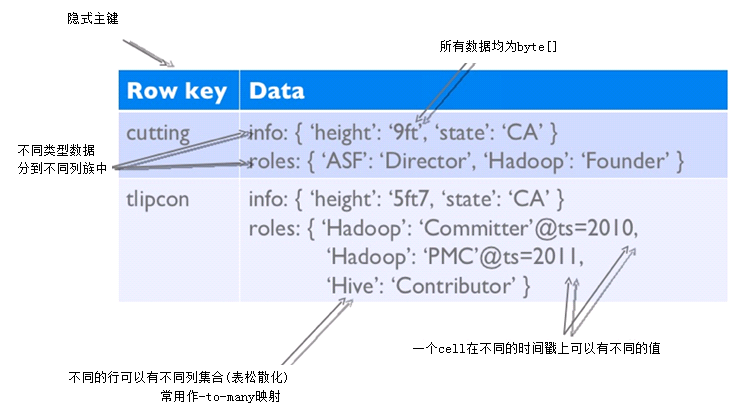
Hbase key和列族

-
key
-
字节数组
-
表主键用于快速查找
-
-
列族
-
有名称
-
包含若干列
-
-
列
-
属于某个列族
-
包含在row内
-
-
版本号
-
key内唯一
-
默认系统时间戳
-
long型
-
-
value(cell)
- byte[]
Hbase数据模型注意事项
-
Hbase schema由表构成
-
表由列族构成
-
列不是schema的部分
-
cell可有动态列
-
列名编码在cell内部
-
版本号可以由用户提供
-
甚至可以不以增序插入
-
在key内唯一
-
-
表可以很松散
- 有很多空cell
-
key作为主键进行索引
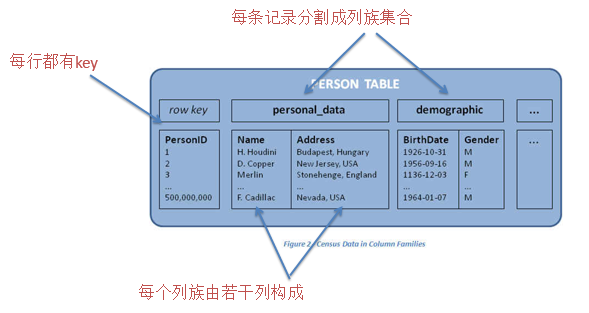
Hbase物理模型
-
每个列族存储在单独的文件中(HTable)
-
Key和版本号会随着每个列族进行复制
-
空cell不存储


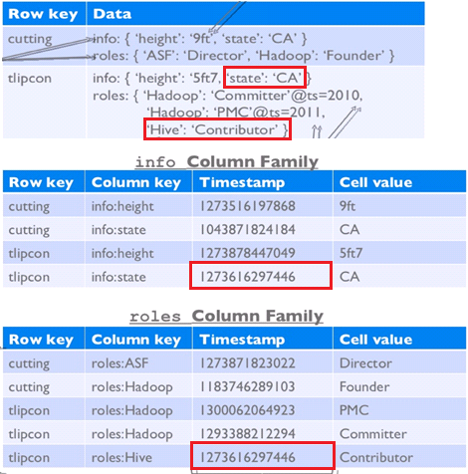
Hbase-列族
-
不同的列可有不用的属性和访问模式
-
列族是可配置的
-
压缩(None,gzip,LZO)
-
版本保留策略
-
缓存优先级
-
-
在磁盘上CF(列族)被单独存储,访问其中的一个,其他不需要浪费IO
Hbase-Region
-
每张HTable(列族)被水平进行了分区,形成Region
- Region区域和hdfs的block相对应

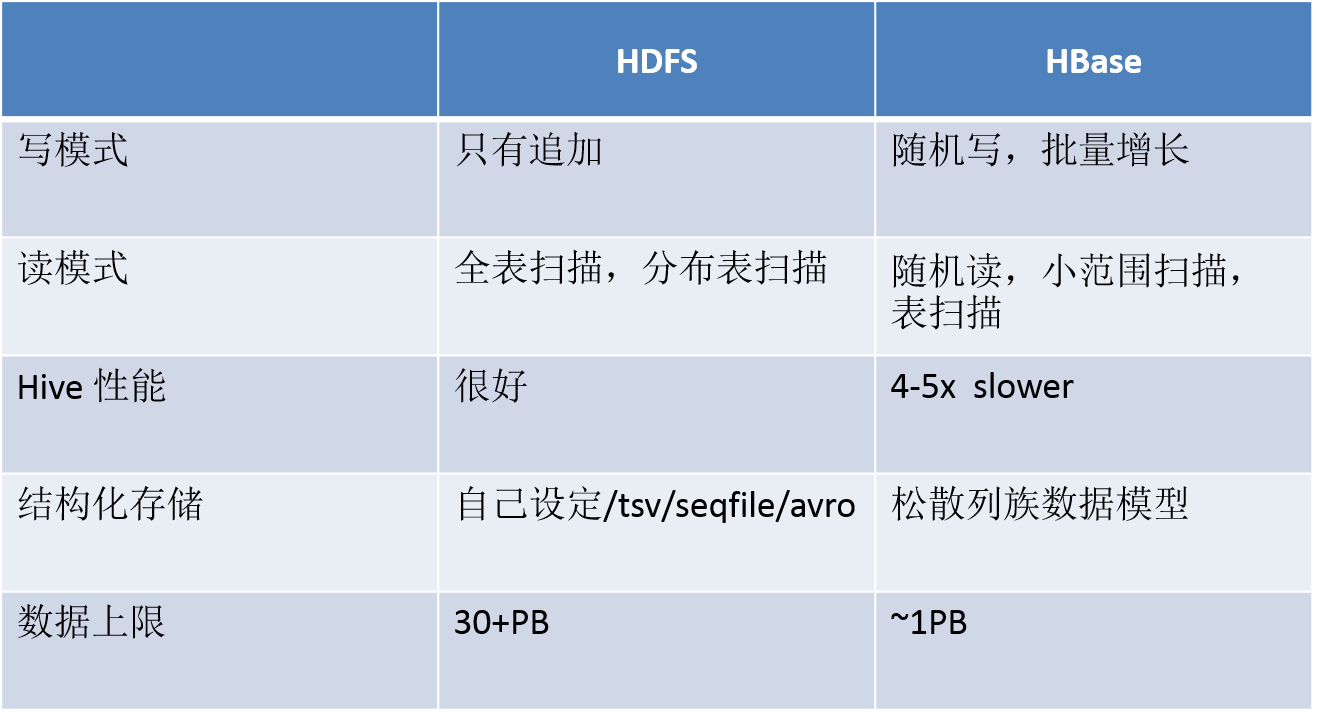
Hbase与HDFS比较
-
都是分布式系统,都可以扩展到成百上千的节点
-
HDFS擅长扫描大文件
-
HDFS不擅长记录查询
-
HDFS不擅长小批量递增
-
HDFS不擅长更新
-
HBase为高效寻址而设计
-
HBase查找记录更快
-
HBase支持记录级别的插入
-
HBase支持更新
-
HBase的更新是通过创建数据的新版本完成的
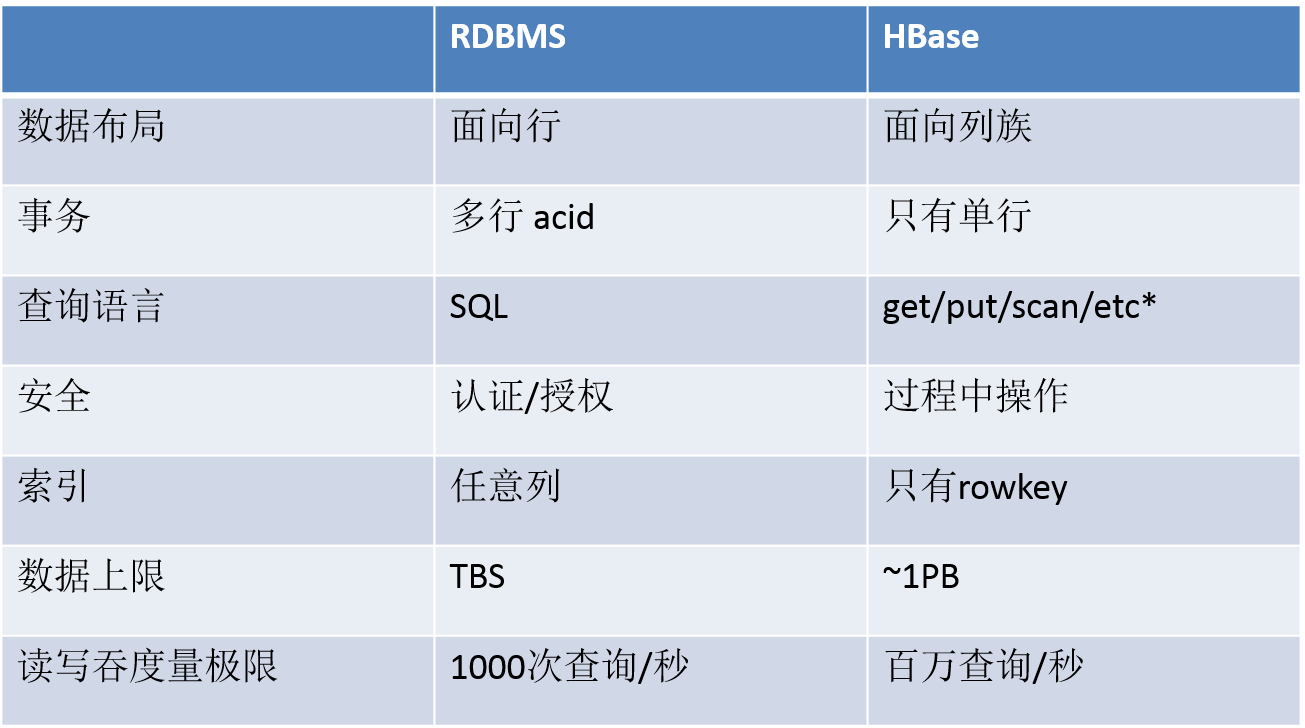
Hbase与RDBMS比较
Hbase使用场景
-
随机写、随机读、兼而有之
-
在TB级数据上每秒做上千次操作
-
访问模式是大家熟知的并是简单的