深入 JVM 内核—原理、诊断与优化之: 性能监控工具 (七)
外部工具
uptime

-
系统时间
-
运行时间
- 例子中为31天8小时8分
-
连接数
- 每一个终端算一个连接
-
1,5,15分钟内的系统平均负载
- 运行队列中的平均进程数,值越大负载越重
top
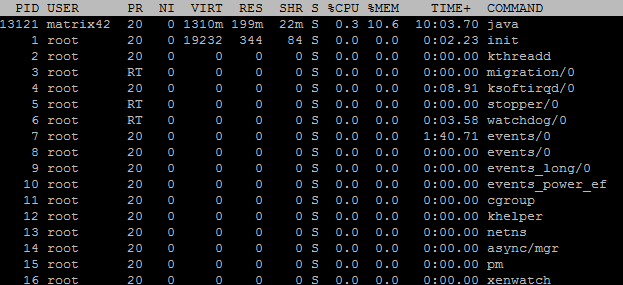
- 可以知道哪个程序占CPU/内存最多
vmstat
- 可以统计系统的CPU,内存,swap,io等情况

-
后面两个参数表示采样频率和采样次数
-
r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
-
b 表示阻塞的进程
-
swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
-
buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存
-
cache cache直接用来记忆我们打开的文件,给文件做缓冲(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
-
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
-
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
-
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
-
bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
-
in 每秒CPU的中断次数,包括时间中断
-
cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
-
us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
-
sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
-
id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
-
wt 等待IO CPU时间。
pidstat
- 执行pidstat,将输出系统启动后所有活动进程的cpu统计信息
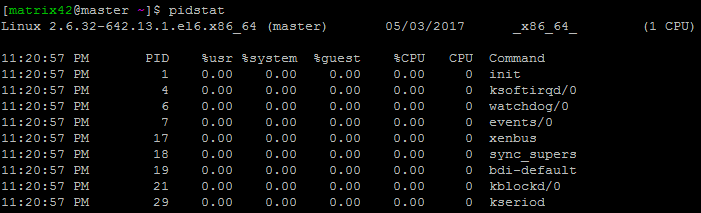
-
指定采样周期和采样次数 pidstat 2 10
-
cpu使用情况统
使用-u选项,pidstat将显示各活动进程的cpu使用统计,执行”pidstat -u”与单独执行”pidstat”的效果一样
-
内存使用情况统计
使用-r选项,pidstat将显示各活动进程的内存使用统计

以上各列输出的含义如下:
minflt/s: 每秒次缺页错误次数(minor page faults),次缺页错误次数意即虚拟内存地址
映射成物理内存地址产生的page fault次数
majflt/s: 每秒主缺页错误次数(major page faults),当虚拟内存地址映射成物理内存地址时,相
应的page在swap中,这样的page fault为major page fault,一般在内存使用紧张时产生
VSZ: 该进程使用的虚拟内存(以kB为单位)
RSS: 该进程使用的物理内存(以kB为单位)
%MEM: 该进程使用内存的百分比
Command: 拉起进程对应的命令-
IO情况统计
使用-d选项,我们可以查看进程IO的统计信息
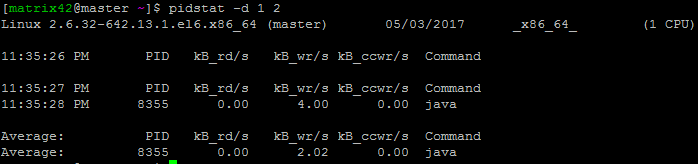
输出信息含义
kB_rd/s: 每秒进程从磁盘读取的数据量(以kB为单位)
kB_wr/s: 每秒进程向磁盘写的数据量(以kB为单位)
Command: 拉起进程对应的命令-
针对特定进程统计
使用-p选项,我们可以查看特定进程的系统资源使用情况
-
pidstat常用命令
pidstat -u 1
pidstat -r 1
pidstat -d 1以上命令以1秒为信息采集周期,分别获取cpu、内存和磁盘IO的统计信息。
pslist(windows)
pslist可以显示当前进程的很多重要信息,并进行一些控制操作
Java自带的工具
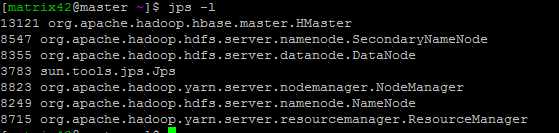
jps
-
列出java进程,类似于ps命令
-
参数-q可以指定jps只输出进程ID ,不输出类的短名称
-
参数-m可以用于输出传递给Java进程(主函数)的参数
-
参数-l可以用于输出主函数的完整路径
-
参数-v可以显示传递给JVM的参数
jinfo
-
可以用来查看正在运行的Java应用程序的扩展参数,甚至支持在运行时,修改部分参数
-
-flag
:打印指定JVM的参数值 -
-flag [+|-]
:设置指定JVM参数的布尔值 -
-flag
= :设置指定JVM参数的值

-表示没有开启
jmap
-
生成Java应用程序的堆快照和对象的统计信息
-
jmap -histo 8249 > jmap.txt
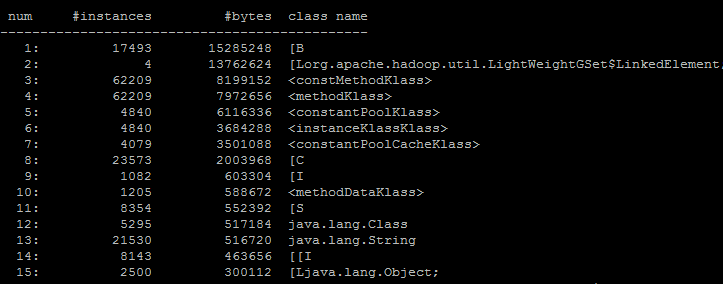
- 输出结果说明
[C is a char[]
[S is a short[]
[I is a int[]
[B is a byte[]
[[I is a int[][]输出中[C对象占用Heap多,往往跟String有关,String其内部使用final char[]数组来保存数据的
constMethodKlass/ methodKlass/ constantPoolKlass/ constantPoolCacheKlass/ instanceKlassKlass/ methodDataKlass与Classloader相关,常驻与Perm区。
-
Dump堆
jmap -dump:format=b,file=c:\heap.hprof 2972

可以使用mat内存分析工具查看
jstack
-
打印线程dump
-
-l 打印锁信息
-
-m 打印java和native的帧信息
-
-F 强制dump,当jstack没有响应时使用
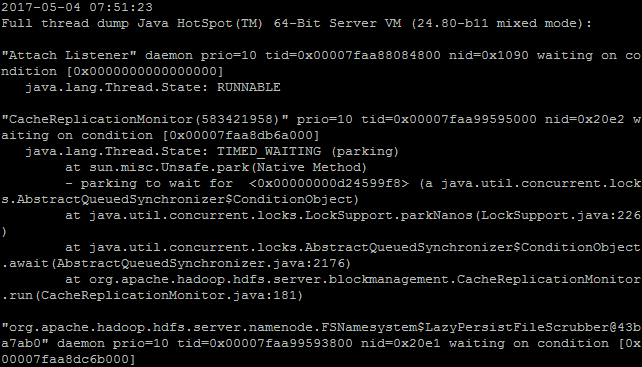
-
tid为线程的id,指Java应用中的id
-
nid为操作系统中的id
-
java.lang.Thread.State为线程运行状态
图形化工具
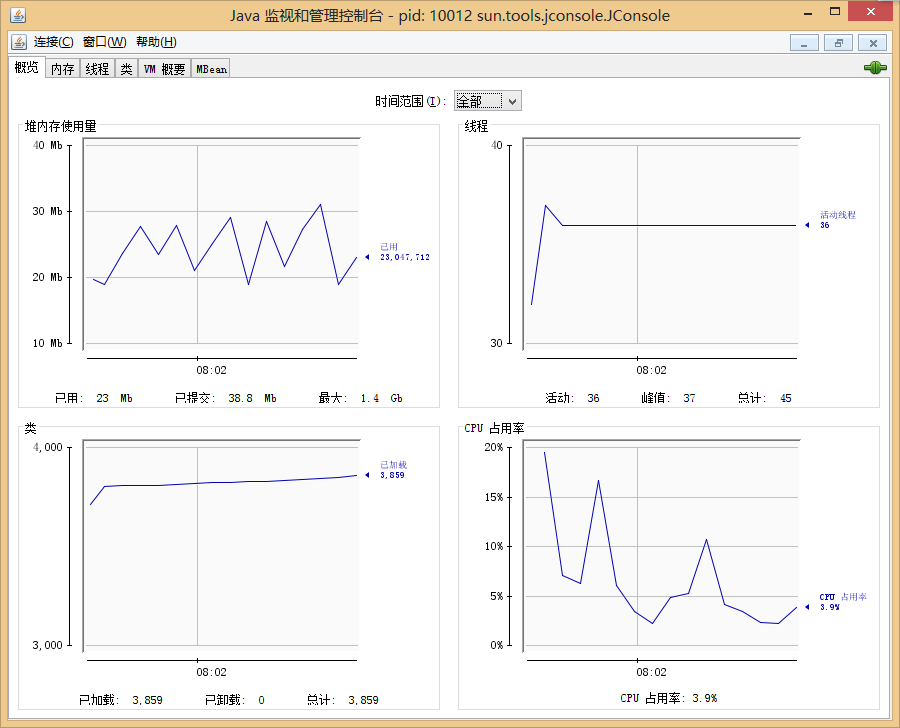
Jconsole
- 可以查看Java应用程序的运行概况,监控堆信息、永久区使用情况、类加载情况等
Visual VM
- Visual VM是一个功能强大的多合一故障诊断和性能监控的可视化工具
- 抽样器可查看cpu占用情况