Hudi写MOR表性能问题分析
Flink版本:1.14
Hudi版本:0.8.0
背景
测试发现当使用MOR(Merge On Read)表的时候写入速度很慢
问题原因
对环境和代码进行分析,发现有2个问题
- 测试环境使用的是虚拟机,IO速度很慢
- Hudi代码有问题
下面对代码问题进行分析
问题分析
hudi有个参数write.batch.size.MB,用来配置写数据时的缓存大小,默认是128M,当缓存的数据超过阈值的时候就会向文件系统写数据。
StreamWriteFunction的bufferRecord方法:
private void bufferRecord(I value) {
final String bucketID = getBucketID(value);
DataBucket bucket =
this.buckets.computeIfAbsent(
bucketID,
k -> new DataBucket(this.config.getDouble(HudiOptions.WRITE_BATCH_SIZE)));
boolean needFlush = bucket.detector.detect(value);
if (needFlush) {
flushBucket(bucket);
bucket.reset();
}
bucket.records.add((HoodieRecord<?>) value);
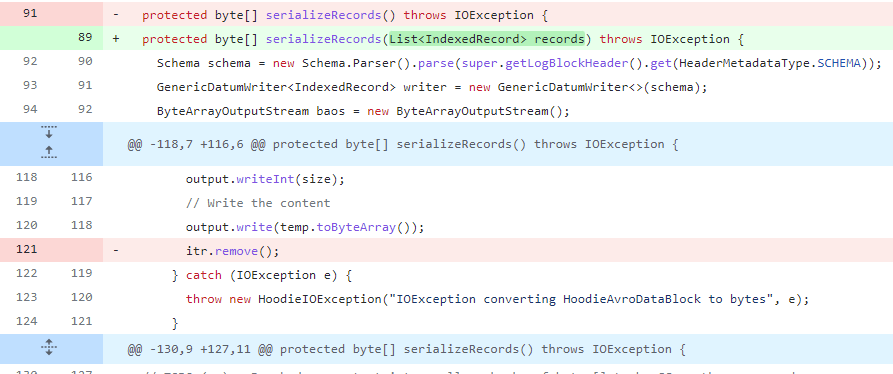
}问题出在写数据的时候,所有数据被放在一个List中,而这个List还是ArrayList,可能是为了GC友好的原因,Hudi在每写入一条数据的时候会将它从列表中移除,问题就出现在这。
当用户将write.batch.size.MB配置的比较大或者每条数据大小比较小的时候,列表中就会缓存大量数据,当调用remove方法的时候就会非常耗时,使原来O(n)复杂度的操作变为O(n^2)。
@Override
protected byte[] serializeRecords() throws IOException {
Schema schema = new Schema.Parser().parse(super.getLogBlockHeader().get(HeaderMetadataType.SCHEMA));
GenericDatumWriter<IndexedRecord> writer = new GenericDatumWriter<>(schema);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
DataOutputStream output = new DataOutputStream(baos);
// 1. Write out the log block version
output.writeInt(HoodieLogBlock.version);
// 2. Write total number of records
output.writeInt(records.size());
// 3. Write the records
Iterator<IndexedRecord> itr = records.iterator();
while (itr.hasNext()) {
IndexedRecord s = itr.next();
ByteArrayOutputStream temp = new ByteArrayOutputStream();
BinaryEncoder encoder = EncoderFactory.get().binaryEncoder(temp, encoderCache.get());
encoderCache.set(encoder);
try {
// Encode the record into bytes
writer.write(s, encoder);
encoder.flush();
// Get the size of the bytes
int size = temp.toByteArray().length;
// Write the record size
output.writeInt(size);
// Write the content
output.write(temp.toByteArray());
//当数据量很大的时候remove操作很费时
itr.remove();
} catch (IOException e) {
throw new HoodieIOException("IOException converting HoodieAvroDataBlock to bytes", e);
}
}
output.close();
return baos.toByteArray();
}解决问题
解决办法也非常简单将itr.remove();这行代码移除即可。因为这个List是另一个方法的局部变量,当数据写完的时候就没有引用了,JVM会自动处理。
题外话
本想把这个问题提交到社区发现有人已经在一个feature中顺便把这个问题解决了,可能是使用的时候发现了这个问题吧。