数据结构与算法之: 树 (六)
树的定义
-
树(Tree)是n(n>=0)个结点的有限集.当n=0时称为空树,在任意一颗非空树中:
-
有且仅有一个特定的称为根(Root)的结点
-
当n>1时,其余结点可分为m(m>0)个互不相交的有限集T1,T2....Tm,其中每个集合本身又是一棵树,并且称为根的子树(SubTree)
-
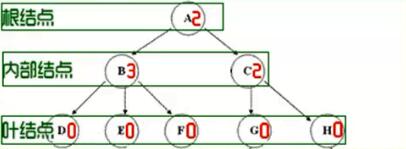
结点分类
-
结点拥有的子树的个数称为结点的度(Degree),树的度取树内各结点的度的最大值.
-
度为0的结点称为叶结点(Leaf)或终端结点
-
度不为0的结点称为分之结点或非终端结点,除根节点外,分支结点也成为内部节点
-
结点间的关系
-
结点的子树的根称为结点的孩子(Child),相应的,该节点称为孩子的双亲(Parent),同一双亲的孩子之间互称为兄弟(Sibling)
-
结点的祖先是从根到该节点所经分支上的所有节点
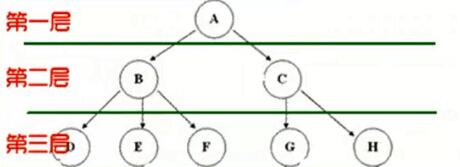
结点的层次
-
结点的层次(Level)从根开始为第一层,根的孩子为第二层
-
其双亲在同一层的结点互为堂兄弟
-
树中结点的最大层次称为树的深度(Depth)或高度
其他概念
-
如果将树中结点的各个子树看成从左至右是有次序的,不能互换的,则称该树为有序树,否则称为无序树
-
森林(Forest)是m(m>0)棵互不相交的树的集合.对树中每个结点而言,其子树的集合即为森林
树的存储结构
- 孩子双亲表示法
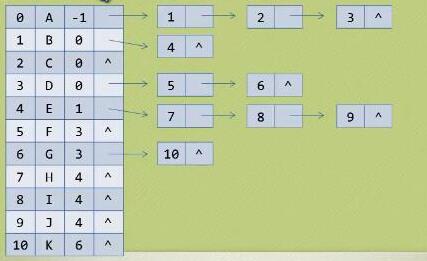
#define MAX_TREE_SIZE
typedef char ElemType;
//孩子结点
typedef struct CTNode
{
//孩子结点的下标
int child;
struct CTNode *next;
}*ChildPtr;
//表头结构
typedef struct
{
//存放在树中的结点的数据
ElemType data;
//双亲的下标
int parent;
//指向第一个孩子的结构
ChildPtr firstchild;
}CTBox;
//树结构
typedef struct
{
//结点数组
CTBox nodes[MAX_TREE_SIZE];
}二叉树
-
二叉树的定义
-
二叉树(Binary Tree)是n(n>=0)个结点的有限集合,该集合或者为空集(空二叉树),或者由一个根节点和两颗互不相交的,分别称为根节点的左子树和右子树的二叉树组成
-
这个定义显然是递归形式的
-
-
二叉树的特点
-
每个结点最多有两颗子树,所以二叉树中不存在度大于2的结点
-
左子树和右子树是有顺序的,次序不能颠倒
-
即使树中某结点只有一颗子树,也要区分它是4左子树还是右子树
-
-
特殊二叉树
-
斜树
-
满二叉树
-
在一颗二叉树中,如果所有分支结点都存在左子树和右子树,并且所有叶子结点都在同一层上,这样的二叉树称为满二叉树
-
叶子结点只能出现在最下一层
-
非叶子结点的度一定是2
-
在同样深度的二叉树中,满二叉树的结点个数一定最多,同时叶子结点也是最多
-
-
完全二叉树
-
对一颗树具有n个结点的二叉树按层序编号,如果编号为i(1<=i<=n)的结点与同样深度的满二叉树中编号为i的结点位置完全相同,则这颗二叉树称为完全二叉树
-
叶子结点只能出现在最下两层
-
最下层的叶子一定集中在左部连续位置
-
倒数第二层,若有叶子结点,一定都在右部连续位置
-
如果结点度为1,则该节点只有左孩子
-
同样节点数的二叉树,完全二叉树的深度最小
-
-
满二叉树一定是完全二叉树,完全二叉树不一定是满二叉树
-
二叉树的性质
-
在二叉树的第i层至多有2^(i-1)个结点(i>=1)
-
深度为k的二叉树至多有2^k-1个结点(k>=1)
-
对任何一颗二叉树T,如果其终端节点数为n0,度为2的结点数为n2,则n0=n2+1
-
具有n个结点的完全二叉树的深度为floor(log2n)+1
-
满二叉树的深度为k=log2(n+1)
-
对于倒数第二层的满二叉树我们同样很容易回推它的节点数为n=2^(k-1)-1
-
所以完全二叉树的节点数的取值范围是:2^(k-1)<n<2^k-1
-
二叉树的存储结构
typedef struct BiTNode
{
ElemType data;
struct BiTNode *lchild,*rchild;
}BiTnode,*BiTree;二叉树的遍历
- 二叉树的遍历(traversing binary tree)是指从根节点出发,按照某种次序依次访问二叉树中所有节点,使得每个结点被访问一次且仅被访问一次
二叉树的遍历方法
-
二叉树的遍历方式可以很多,如果我们限制了从左到右的习惯方式,那么主要就分为以下四种:
-
前序遍历
-
中序遍历
-
后序遍历
-
层次遍历
-
-
前序遍历:
- 若二叉树为空,则返回,否则县访问根节点,然后前序遍历左子树,再前序遍历右子树
-
中序遍历
- 若树为空,则返回,否则从根节点开始(并不是访问根节点),中序遍历根节点的左子树,然后是访问根节点,最后中序遍历右子树
-
后序遍历
- 若树为空,则返回,否则从左到右先叶子后结点的方式遍历访问左右子树,左后访问根节点
-
层次遍历
- 若树为空,则返回,否则从树的第一层,也就是根节点开始访问,从上而下逐层遍历,在同一层中,按从左到右的顺序对结点逐个访问
#include <stdio.h>
#include <stdlib.h>
typedef char ElemType;
typedef struct BiTNode
{
ElemType data;
struct BiTNode *lchild,*rchild;
}BiTNode,*BiTree;
//创建一颗二叉树,约定用户遵照前序遍历的方式输入数据
void CreateBiTree(BiTree *T)
{
char c;
scanf("%c",&c);
if(' '==c)
{
*T = NULL;
}
else
{
*T = (BiTNode *)malloc(sizeof(BiTNode));
(*T)->data = c;
CreateBiTree(&(*T)->lchild);
CreateBiTree(&(*T)->rchild);
}
}
//访问二叉树结点的具体操作
void visit(char c,int level)
{
printf("%c位于第%d层\n",c,level);
}
//前序遍历二叉树
void PreOrderTraverse(BiTree T,int level)
{
if(T)
{
visit(T->data,level);
PreOrderTraverse(T->lchild,level+1);
PreOrderTraverse(T->rchild,level+1);
}
}
//中序遍历二叉树
void InOrderTraverse(BiTree T,int level)
{
if(T)
{
InOrderTraverse(T->lchild,level+1);
visit(T->data,level);
InOrderTraverse(T->rchild,level+1);
}
}
//后序遍历二叉树
void PostOrderTraverse(BiTree T,int level)
{
if(T)
{
PostOrderTraverse(T->lchild,level+1);
PostOrderTraverse(T->rchild,level+1);
visit(T->data,level);
}
}
int main()
{
int level = 1;
BiTree T = NULL;
CreateBiTree(&T);
PreOrderTraverse(T,level);
return 0;
}线索二叉树
- 由于二叉树的叶子节点会有很多指针被浪费了,我们考虑能不能把浪费的空间利用起来
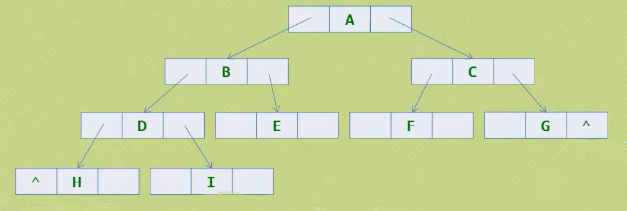
-
二叉树只能从双亲结点找到孩子节点,我们可以把指针利用起来,哪种遍历方式可以更好的利用叶子节点的指针呢?
-
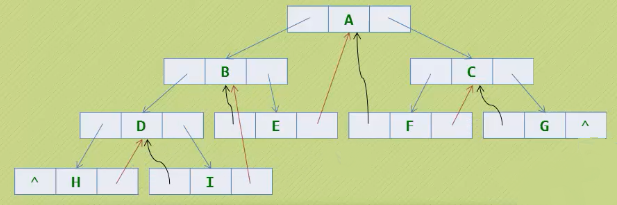
前序遍历:A B D H I E C F G
-
中序遍历:H D I B E A F C G
-
我们可以看出来中序遍历可以更好的利用指针,两个指针分别指向前驱和后继节点
-
黑色的线指向前驱节点,红色的线指向后继节点
-
将定义好的结构扩容:
lchild ltag data rtag rchild-
ltag为0时指向该节点的左孩子,为1时指向该节点的前驱
-
rtag位0时指向该节点的右孩子,为1时指向该节点的后继
-
#include <stdio.h>
#include <stdlib.h>
typedef char ElemType;
//线索存储标志位
//Link(0):表示指向左右孩子的指针
//Thread(1):表示指向前驱后继的线索
typedef enum {Link,Thread} PointerTag;
typedef struct BiThrNode
{
ElemType data;
struct BiThrNode *lchild,*rchild;
PointerTag ltag;
PointerTag rtag;
}BiThrNode,*BiThrTree;
//全局变量,始终指向刚刚访问过的结点
BiThrTree pre;
//创建一颗二叉树,约定用户遵照前序遍历的方式输入数据
void CreateBiThrTree(BiThrTree *T)
{
char c;
scanf("%c",&c);
if(' '==c)
{
*T = NULL;
}
else
{
*T = (BiThrNode *)malloc(sizeof(BiThrNode));
(*T)->data = c;
(*T)->ltag = Link;
(*T)->rtag = Link;
CreateBiThrTree(&(*T)->lchild);
CreateBiThrTree(&(*T)->rchild);
}
}
void InThreading(BiThrTree T)
{
if(T)
{
//递归左孩子线索化
InThreading(T->lchild);
//处理结点
//如果该节点没有左孩子,设置ltag为Thread
//并把lchild指向刚刚访问的结点
if(!T->lchild)
{
T->ltag = Thread;
T->lchild = pre;
}
if(!pre->rchild)
{
pre->rtag = Thread;
pre->rchild = T;
}
pre = T;
//递归右孩子线索化
InThreading(T->rchild);
}
}
void InOrderThreading(BiThrTree *p,BiThrTree T)
{
*p = malloc(sizeof(BiThrTree));
(*p)->ltag = Link;
(*p)->rtag = Thread;
(*p)->rchild = *p;
if(!T)
{
(*p)->lchild = *p;
}
else
{
(*p)->lchild = T;
pre = *p;
InThreading(T);
pre->rchild = *p;
pre->rtag = Thread;
(*p)->rchild = pre;
}
}
void visit(char c)
{
printf("%c",c);
}
//中序遍历二叉树,非递归
void InOrderTraverse(BiThrTree T)
{
BiThrTree p;
p = T->lchild;
while(p!=T)
{
while(p->ltag==Link)
{
p = p->lchild;
}
visit(p->data);
while(p->rtag == Thread && p->rchild != T)
{
p = p->rchild;
visit(p->data);
}
p = p->rchild;
}
}
int main()
{
//ABC^^D^^E^F^^^
BiThrTree P,T = NULL;
CreateBiThrTree(&T);
InOrderThreading(&P,T);
printf("中序遍历结果为:");
InOrderTraverse(P);
printf("\n");
return 0;
}树,森林以及二叉树的相互转换
-
普通树转换为二叉树
-
加线:在所有兄弟结点之间加一条线
-
去线:对树中每个结点,只保留它与第一个孩子结点的连线,删除它与其他孩子结点之间的连线
-
层次调整:以树的根节点为轴心,将整棵树顺时针旋转一定角度,使之结构层次分明
-
-
森林转换为二叉树
-
把每棵树转换为二叉树
-
第一棵二叉树不动,从第二棵二叉树开始,依次把后一颗二叉树的根节点作为前一棵二叉树的根节点的右孩子,用线连接起来
-
-
二叉树转换为树,森林
-
二叉树转换为普通树是刚才的逆过程,步骤是反过来做
-
判断一颗二叉树能够转换成一棵树还是森林,标准很简单,那就是只要看这颗二叉树的根节点有没有右孩子,有的话就是森林,没有的话就是一棵树
-
树与森林的遍历
-
树的遍历分为两种方式:一种是先根遍历,另一种是后根遍历
-
先跟遍历:先访问树的根节点,然后再依次先根遍历根的每棵子树
-
后根遍历:先依次遍历每棵子树,然后再访问根节点
-
森林的遍历也分为前序遍历和后序遍历,其实是按照树的先根遍历和后根遍历依次访问森林的每一棵树
-
我们发现:树,森林的前根遍历和二叉树的前序遍历结果相同,树,森林的后根遍历和二叉树的中序遍历结果相同
-
我们找到了对树和森林遍历这种复杂问题的简单解决方案
赫夫曼树
-
在数据膨胀,信息爆炸的今天,数据压缩的意义不言而喻.谈到数据压缩,就不能不提赫夫曼(Huffman)编码,赫夫曼编码是首个实用的压缩编码方案,即使在今天的许多知名压缩算法里,依然可以见到赫夫曼编码的影子
-
另外,在数据通信中,用二进制给每个字符进行编码时,不得不面对的一个问题是如何使电文总长最短且不产生二义性.根据字符出现频率,利用赫夫曼编码可以构造出一种不等长的二进制,使编码后的电文长度最短,且保证不产生二义性
-
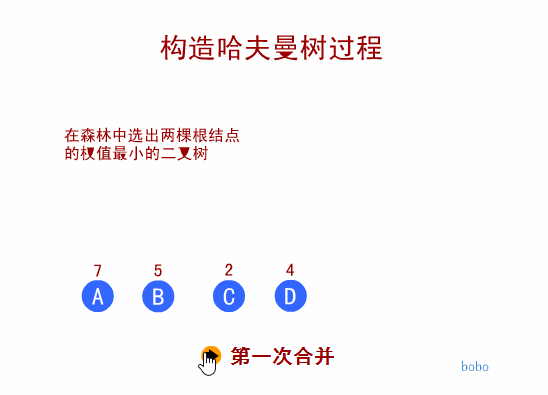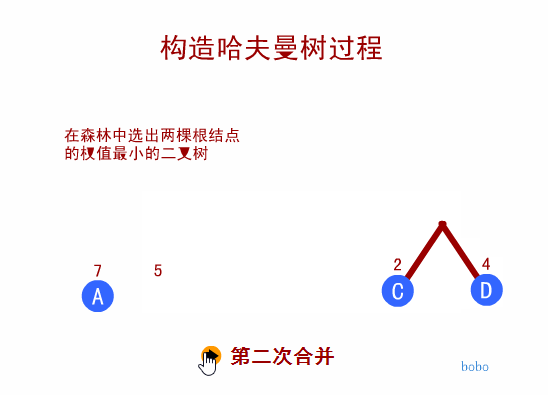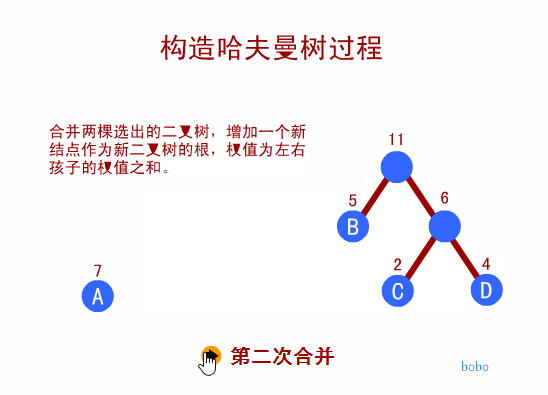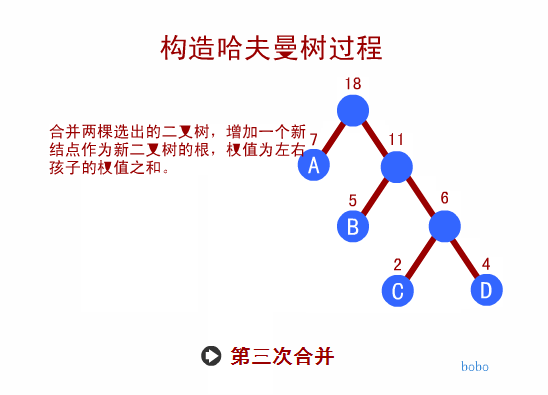
赫夫曼树定义与原理
- 我们先把这两棵二叉树简化成叶子结点带权的二叉树(注:树结点间的连线相关的数叫做权,Weight)
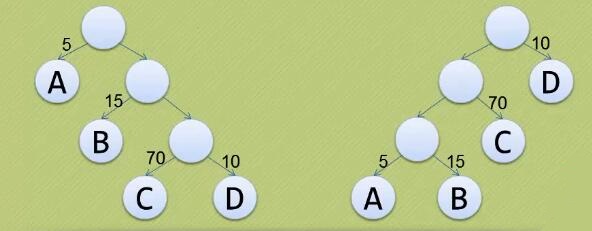
* 结点的路径长度:从根结点到该结点的路径上的连接数
* 树的路径长度:树中每个叶子结点的路径长度之和
* 结点带权路径长度:结点的路径长度与结点权值的乘积
* 树的带权路径长度:WPL(Weighted Path Length)是树中所有叶子结点的带权路径长度之和-
WPL的值越小,说明构造出来的二叉树性能越优
-
WPL值最小的二叉树为最优二叉树