数据结构与算法之: 查找 第二部分 (十)
多路查找树(multi-way search tree)
-
多路查找树的特点是其每一个节点的孩子数可以多余两个,且每一个节点处可以存储多个元素
-
所有元素之间存在某种特定的排序关系
-
存储
当在磁盘的很多文件中查找一个文件时,会把磁盘中的内容加载到内存中,加载几千次和几次的差别是非常大的,多路查找树在减少磁盘io操作能起到很好的作用
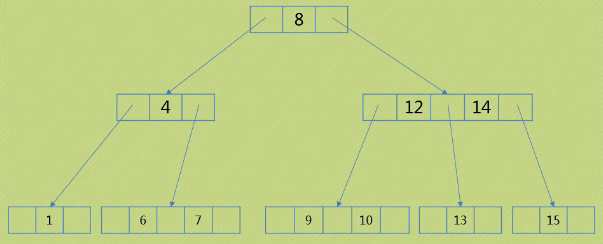
2-3树
-
一个节点拥有两个孩子和一个元素我们称之为2节点,它跟二叉排序树类似,左子树包含的元素小于节点的元素,右子树包含的元素大于节点的元素.不过与二叉排序树不同的是,这个2节点要么没有孩子,要么就应该有两个孩子,不能只有一个孩子
-
3节点拥有2个数据元素和3个指针
2-3-4树
与2-3树类似
B树
-
B树(B-tree)是一种平衡的多路查找树,2-3树和2-3-4树都是B树的特例
-
我们把节点最大的孩子树目称为B树的阶(order),因此2-3树是3阶B树,2-3-4树是4阶B树
-
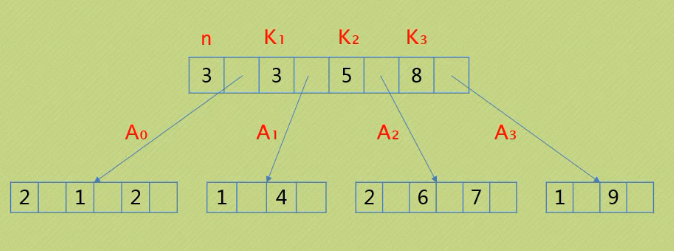
一个m阶的B树具有如下属性:
-
如果根结点不是叶结点,则其至少有两颗子树
-
每一个非根的分支结点都有k-1个元素(关键字)和k个孩子,其中k满足ceil(m/2)<=k<=m
-
所有叶子结点都位于同一层次
-
每一个分支结点包含下列信息数据:n,A0,K1,K2,A2,K3,A3......
-
其中K为关键字,且Ki<Ki+1
-
Ai为指向子树根节点的指针
-
-
散列表(哈希表)查找
介绍
-
我们要在a[]中查找key关键字的记录
-
书序查找:挨个比较
-
有序表查找:二分查找
-
散列表查找:记录的存储位置=f(关键字)
-
-
散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)
-
在这里我们把这种对应关系f称为散列函数,又称为哈希(Hash)函数.采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)
散列表的查找步骤
-
当存储记录时,通过散列函数计算出记录的散列地址
-
当查找记录时,我们通过同样的散列函数计算记录的散列地址,并按此散列地址访问该记录
构造散列函数的两个基本原则
-
计算简单
-
分布均匀
直接定址法
-
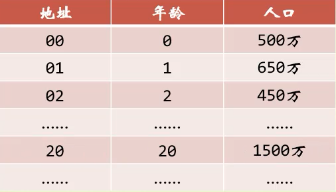
例一:有一个从1到100岁的人口统计表,其中年龄作为关键字,哈希函数取关键字自身
-
即f(key)=key
-
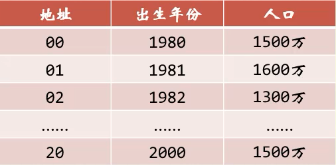
例二:如果现在要统计的是1980年以后出生的人口数,那么我们对出生年份这个关键字可以变换为:用年份减去1980的值作为地址
-
即:f(key) = key - 1980
-
我们可以取关键字的某个线性函数值为散列地址,即:f(key)=a*key+b
-
适合查找表比较小,并且连续的情况
数字分析法
- 数字分析法通常适合处理关键字位数比较大的情况,例如我们现在要存储某家公司员工登记表,如果用手机号作为关键字,那么我们发现抽取后面四位数字作为散列地址是不错的选择
平方取中法
-
平方取中法是将关键字平方之后取中间若干位数字作为散列地址
-
适合数字较小的情况
折叠法
-
折叠法是将关键字从左到右分割成位数相等的几部分,然后将这几部分叠加求和,并按散列表表长取后几位作为散列地址
-
比如表长为3,关键字为9876543210,分割补齐:987|654|321|000,相加取后3位,得962
除留余数法
-
此方法为最常用的构造散列函数方法,对于散列表长度为m的散列函数计算公式为:f(key) = ley mod p(p<=m)
-
事实上,这个方法不仅可以对关键字直接取模,也可以通过折叠,平方取中后再取模
-
例如下表,我们对有12个记录的关键字构造散列表时,就可以用f(key) = key mod 12的方法

- p的选择是关键,如果对于这个表格的关键字,p还选12的话,那么的到的情况未免也太糟糕了

- p的选择很重要,如果我们把p改为11,那结果就另当别论了

随机数法
-
选择一个随机数,取关键字的随机函数值为它的散列地址
-
即:f(key) = random(key)
-
这里的random是随机函数,当关键字的长度不等时,采用这个方法构造散列函数是比较合适的
视不同的情况采用不同的散列函数
-
计算散列地址所需的时间
-
关键字的长度
-
散列表的大小
-
关键字的分布情况
-
记录查找的频率
处理散列冲突的方法
-
开放地址法
所谓开放地址法就是一旦发生了冲突,就寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入
-
公式
fi(key) = (f(key)+di) MOD m (di=1,2,...,m-1)
-
例:假设关键字集合为{12,67,56,16,25,37,22,29,15,47,48,34},使用除留余数打法(m=12)求散列表


-
可以修改di的取值方式,例如使用平方运算来尽量解决堆积问题:
fi(key) = (f(key)+di) MOD m (di=1^2,-1^2,2^2,-2^2,...,q^2,-q^2,q<=M/1)
-
还有一种方法是,在冲突时,对于位移量di,采用随机函数计算得到,我们称之为随机探测法:
fi(key) = (f(key)+di) MOD m (di是由一个随机函数获得的数列)
再散列函数法
-
fi(key) = RHi(key) (i=1,2,3,...,k)
每个i对应一个散列函数,如果使用当前散列函数发生冲突则使用下一个散列函数
链地址法
-
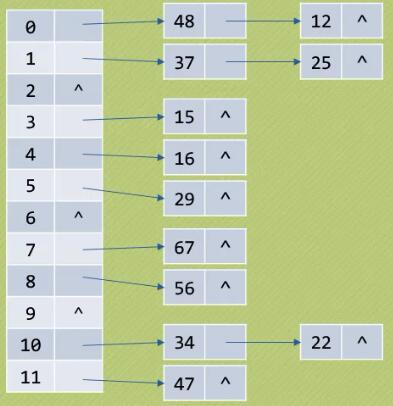
假设关键字集合为{12,67,56,16,25,37,22,29,15,47,48,34},同样使用除留余数发求散列表
-
有同样hash值得元素放在同一个地方的链表里
公共溢出区法
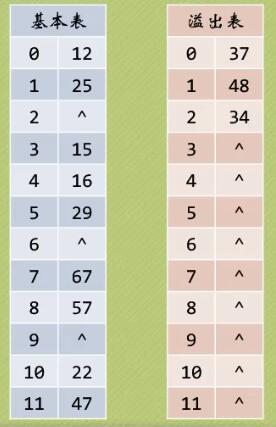
- 假设关键字集合为{12,67,56,16,25,37,22,29,15,47,48,34},同样使用除留余数发求散列表
散列表查找的代码实现
#define HASHSIZE 12
#define NULLKEY -32768
typedef struct
{
int *elem; //数据元素的基址,动态分配数组
int count; //当前数据元素的个数
}HashTable;
void InitHashTable(HashTable *H)
{
int i;
H->count = HASHSIZE;
H->elem = (int *)malloc(HASHSIZE * sizeof(int));
if(!H->elem)
{
return -1;
}
for(i=0;i<HASHSIZE;i++)
{
H->elem[i] = NULLKEY;
}
return 0;
}
//使用除留余数发
int Hash(int key)
{
return key % HASHSIZE;
}
//插入关键字到散列表
void InsertHash(HashTable *H,int key)
{
int addr;
addr = Hash(key);
while(H->elem[addr]!=NULLKEY)//如果冲突
{
addr = (addr + 1) % HASHSIZE; //开发定址法的线性探测
}
H->elem[addr] = key;
}
int SearchHash(HashTable H,int key,int *addr)
{
*addr = Hash(key);
while(H.elem[*addr] != key)
{
*addr = (*addr + 1) % HASHSIZE;
if(H.elem[*addr] == NULLKEY || *addr == Hash(key))
{
return -1;
}
}
return 0;
}